Nel primo stadio del sistema visivo dei primati, come in V1, gli oggetti sono codificati in termini di coordinate retinotopiche, e lesioni di quest’area causano difetti nello spazio visivo che mantengono una costante localizzazione retinica.
Nei livelli successivi, in corrispondenza di IT (area inferotemporale), i campi recettivi sono indipendenti dalla localizzazione retinica e i neuroni possono essere attivati da uno stimolo specifico come una faccia. I difetti causati da lesioni IT sono basate sulle proprietà dell’oggetto e indipendenti dalla localizzazione retinica. Nel momento in cui le coordinate spostano il loro centro sull’oggetto, il sistema diviene indipendente dalla precisa metrica dell’oggetto, questo significa che il sistema continua a rispondere all’oggetto, nonostante le variazioni di grandezza, orientamento e tessitura.
Studi sul macaco suggeriscono che per l’analisi delle facce queste trasformazioni avvengono nell’area IT anteriore, mentre la risposta delle cellule, nel solco temporale superiore (STS) è selettiva per l’angolo di presentazione dell’oggetto e la loro informazione in uscita potrebbe essere combinata in IT per produrre una cellula indipendente all’angolo di visualizzazione. Ne consegue che danni selettivi ad IT causano l’incapacità di riconoscere un oggetto che va sotto il nome di agnosia visiva.
L’analisi visiva precoce
Teoria di Marr
David Courtnay Marr tentò di descrivere una teoria dell’analisi della visione degli oggetti . Si basò sulla fisiologia di Hubel e Wiesel e ha suddiviso l’analisi visiva in 4 stadi:
1 LIVELLO: ABBOZZO PRIMARIO GREZZO, descrizione dei bordi e contorni, compresi la loro localizzazione e il loro orientamento
2 LIVELLO ABBOZZO PRIMARIO COMPLETO: Rappresentazione di strutture più grandi come confini e regioni
3 LIVELLO ABBOZZO 2 ½ DIMENSIONALE: Rappresentazione più completa di oggetti su rappresentazioni centrate sull’osservatore, è ottenuta tramite l’analisi della profondità, del movimento e delle strutture assemblate nell’abbozzo primario
4 LIVELLO MODELLO TRIDIMENSIONALE:Rappresentazione centrata sull’oggetto piuttosto che sull’osservatore
Teorie della gestalt

Il riconoscimento visivo può essere descritto anche come la corrispondenza tra l’immagine retinica di un oggetto e la sua rappresentazione immagazzinata in memoria. Affinché ciò accada, la configurazione di punti di diversa intensità a livello delle cellule gangliari deve essere rappresentata in un modello tridimensionale dell’oggetto che pertanto sarà riconoscibile da qualunque angolazione.
L’analisi corticale delle informazioni visive inizia in V1 con l’analisi dell’orientamento dei bordi o contorni.
I principi che guidano il sistema visivo nella costruzione di bordi e dei contorni per formare gli oggetti possono essere ritrovati nel pensiero della Gestalt sulla visione che propone una serie di regole per la definizione dei contorni.
Per esempio, secondo il principio di buona continuità, un bordo è percepito come continuo se gli elementi di cui è composto possono essere congiunti da una linea curva o dritta, originando così le illusioni. Gli psicologi hanno ipotizzato che i contorni definiti dalla buona continuità fossero costruiti a livello centrale ma recenti risultati suggeriscono che i contorni illusori siano estratti a un livello precoce del sistema visivo.
Studi fisiologici hanno mostrato che specifiche popolazioni di cellule, nelle prime aree visive (V1 e V2), rispondono selettivamente all’orientamento dei contorni definiti dalla buona continuità. Inoltre, circa un terzo delle cellule misurate in V2 rispondono bene a contorni illusori che si estendono attraverso interruzioni, tanto quanto a normali contorni di luminanza e mostrano un’equivalente selettività per l’orientamento dei bordi sia reali sia illusori.
Alcuni principi della gestalt

Correlati neurali implicati nella percezione e nel riconoscimento degli oggetti
Le differenze di colore sono rilevate precocemente nel sistema visivo
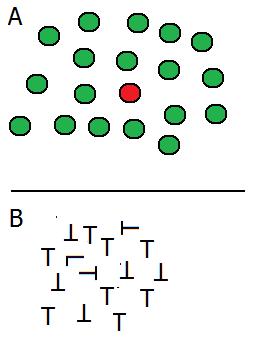
Davis e Driver, al fine di distinguere gli stadi di analisi precoce e tardivi delle informazioni visive hanno utilizzato un compito di ricerca visiva . Per es. una singola lettera rossa è individuata istantaneamente tra molte lettere bianche mescolate (pop-out), ma l’identificazione di una L in mezzo a tante T richiede molto più tempo. Questo risultato dimostra che le differenze di colore siano rilevate precocemente nel sistema visivo, ma la differenziazione di lettere simili è il risultato di un processo più complesso ed avviene ai livelli superiori. Davis e Driver hanno usato figure delineate da contorni illusori basate sul triangolo di Kanizsa, e i loro risultati sono in accordo con un’analisi precoce delle caratteristiche da parte del sistema visivo. Pertanto, le prime aree visive possiedono il meccanismo neurale coinvolto nella definizione dei contorni.
Proprietà e organizzazione dei neuroni nella corteccia IT
Ma mano che si prosegue lungo le aree corticali della scimmia deputate all’analisi degli oggetti (V1 V2 V4 IT posteriore (PIT) e IT anteriore (AIT)) le proprietà di risposta dei neuroni cambiano, il campo recettivo delle cellule s’ingrandisce considerevolmente. Ad es. V1 1 grado, V4 4 gradi, PIT 16 gradi, AIT 150 gradi. L’ingrandimento del campo recettivo permette lo sviluppo di una risposta visiva che non dipende dalla grandezza e dalla posizione dello stimolo nel campo visivo. La cellula, inoltre, può rispondere a stimoli più complessi. In V4 e PIT si è osservato che la maggior parte delle cellule è sensibile alle qualità primarie (colore, dimensione, orientamento) mentre AIT sembrano essere sensibili a forme e configurazioni complesse.
Le modalità con cui le cellule IT codificano gli oggetti appare complesso:
Tanaka ha deciso di determinare le caratteristiche minime necessarie a eccitare una cellula in AIT. La procedura inizia presentando un elevato numero di oggetti mentre si registra la sua risposta, al fine d’individuare l’oggetto che la eccita. A questo punto le sue componenti caratteristiche sono separate e presentate singolarmente o in combinazione. Llo scopo è trovare la più semplice combinazione di caratteristiche a cui la cellula risponde in modo ottimale. Il problema risiede nella difficoltà a presentare tutte le possibili combinazioni di caratteristiche, poiché anche lo stimolo più semplice possederà caratteristiche elementari come profondità, colore, forma, etc.
Tanaka ha osservato una popolazioni di neuroni IT dette cellule elaborate che sembrano rispondere a forme semplici, inoltre ha ipotizzato che cellule strettamente adiacenti generalmente rispondono a configurazioni di caratteristiche simile. Attraverso registrazioni con penetrazioni verticali egli ha osservato che le cellule rispondono allo stesso stimolo ottimale. Questi risultati suggeriscono che le cellule in IT sini organizzate in colonne funzionali o moduli, in maniera simile all’organizzazione di V1.
L’alfabeto visivo: la teoria dei geoni di Biederman
Questo ha dato origine all’idea che le forme semplici formano un alfabeto visivo da cui possa essere costruita la rappresentazione dell’oggetto. Sulla base delle risposte delle cellule elaborate, una rappresentazione potrebbe essere ottenuta in almeno due modi: uno, attraverso una gerarchia in cui cellule elaborate invierebbero un segnale alle cellule dei livelli successiv. Successivamente, l’informazione in uscita da quest’ultime segnalerebbe la presenza di un oggetto complesso alle aree superiori come la corteccia prefrontale. Potrebbero non esserci livelli successivi: l’insieme di risposte fornite dalle varie colonne di cellule elaborate potrebbero direttamente segnalare la presenza di un oggetto complesso a un’area superiore senza dover convergere su una cellula dell’area IT.
Il concetto di alfabeto visivo assume quindi che una cellula IT segnali in modo affidabile la presenza di una particolare forma semplice che la eccita, e quindi un oggetto complesso che comprende questa forma semplice dovrebbe evocare una forte risposta, ma invece non è così; la presenza di altre caratteristiche può conpromettere la risposta della cellula al suo stimolo ottimale.

Biederman ha proposto una teoria del riconoscimento basata sulla scomposizione di oggetti complessi in forme componenti semplici.
Biederman considera un ristretto insieme di forme basilari come cunei e cilindri che ha denominato geoni. Queste descrizioni qualitative potrebbero essere sufficienti a distinguere differenti classi di oggetti, ma non a discriminare all’interno di una classe di oggetti aventi le stesse componenti basi. Inoltre, questo modello è inadeguato a differenziare forme dissimili in cui le similarità percettive delle forme possono indurre a riconoscere simili tra loro oggetti che invece sono composti da geoni diversi.
Oggetti complessi in tre dimensioni
Sin dai primi anni 70 è nota l’esistenza di neuroni, nella corteccia visiva temporale della scimmia, che rispondono alle facce, alle mani e ad altri stimoli biologici complessi. Le cellule selettive per i volti sono localizzate in IT, sui bordi e sulle pareti di STS. Lo stimolo ottimale di una larga proporzione di queste cellule non può essere decomposto in forme più semplici.
In generale le cellule che rispondono alle facce non manifestano alcuna risposta a qualsiasi altro tipo di stimolo presentato, ma rispondono fortemente a una varietà di facce, comprese modelli di plastica, immagini video, e disegni. Le risposte di queste cellule sono indipendenti dalle dimensioni e dalla posizione dello stimolo.
Le cellule per le facce
Le cellule per le facce sono sensibili alla posizione relativa delle caratteristiche all’interno della faccia, in particolare alla distanza tra gli occhi, tra gli occhi e la bocca, la quantità di capelli. Inoltre, la presentazione di una singola frazione facciale evoca solo una frazione di risposta, e la rimozione di una singola componente riduce ma non elimina la risposta della cellula per il volto.
Queste cellule continuano anche a rispondere a immagini di facce sottoposte ad un filtraggio passa-basso o passa-alto, o che abbiano subito l’alterazione del colore o del contrasto. Queste complesse proprietà neuronali suggeriscono che tale classe di cellule sia davvero selettiva per le facce.
La maggior parte delle cellule in AIT e in STS è selettiva per l’angolo di presentazione del volto. Queste cellule sono definite dipendenti dall’angolo di visualizzazione, o centrate sull’osservatore.
Le cellule indipendenti dall’angolo di presentazione dello stimolo, o centrate sull’oggetto, potrebbero derivare dalla combinazione delle risposte di diverse cellule angolo dipendenti. Questo schema gerarchico suggerisce che la latenza di risposte delle cellule angolo indipendenti debba essere più lunga di quella delle cellule angolo dipendenti. Inoltre, studi di registrazione di singole cellule suggeriscono che le cellule sensibili alle facce, come le cellule elaborate abbiano un’organizzazione colonnare.
La cellula della nonna
Le cellule del lobo temporale, selettive alle facce, somigliano superficialmente alle unità gnostiche proposte da Konorski, o alle cellule cardinali proposte da Barlow. Tali cellule sono descritte come unità all’apice della piramide dell’elaborazione visiva. Alla base si troverebbero i rilevatori di linee e bordi nella corteccia striata, successivamente i rilevatori di complessità crescente fino alle ’unità che rappresentono uno specifico oggetto o persona.
Questa ipotesi però presenta seri problemi: infatti, il numero degli oggetti in cui c’imbattiamo durante la nostra vita è enorme, forse molto più grande del numero di neuroni di cui disponiamo, perciò questo metodo di codifica è del tutto inefficiente, poiché ci sarebbe bisogno di un vasto numero di cellule inutilizzate tenute in riserva per codificare nuovi oggetti.
Le cellule selettive per le facce, come le altre cellule IT probabilmente formano una rete distribuita per la codifica delle caratteristiche generali degli oggetti. Le facce sono quindi decodificate dall’attività combinata di popolazioni o insiemi di cellule. questo tipo di codifica permette di far fronte agli svantaggi della teoria della cellula della nonna. Infatti, il numero di facce, o oggetti specifici, codificate da una popolazione di cellule può essere molto più grande del numero di cellule che costituiscono la popolazione, inoltre non è necessaria alcuna riserva di cellule non utilizzata.
Se la popolazione risponde a un grande numero di facce, questa deve essere grande; essa è denominata codifica distribuita. Se una cellula risponde solo a un piccolo numero di facce specifiche, allora solo un esiguo numero di cellule nella popolazione sarà necessario a distinguere un particolare volto; ciò va sotto il nome di codifica limitata. Gli esperimenti di registrazione di singole cellule nell’area IT di scimmia hanno dimostrato che i neuroni sensibili alle facce sono estremamente selettivi e quindi sono in accordo con la codifica limitata.
L’attenzione visiva e la memoria
I processi pre-attentivi, attentivi e la segregazione figura sfondo
La capacità d’immagazzinare e codificare pienamente gli oggetti in memoria da parte dei neuroni è limitata. Desimone ha suggerito che gli oggetti debbano competere per l’attenzione e lo spazio di codifica nel sistema visivo, e che questa competizione può essere influenzata sia da fattori cognitivi sia da fattori automatici.
I fattori automatici sono descritti come processi pre-attentivi (boottom-up), mentre per fattori cognitivi s’intende i processi attentivi (top-down), I fattori preattentivi sono coinvolti con le proprietà intrinseche dello stimolo di una scena, così gli stimoli che differiscono dal loro sfondo avranno il vantaggio competitivo di occupare l’attenzione del sistema visivo e acquisire spazio di codifica.
La separazione di uno stimolo dal suo sfondo è detta segregazione figura-sfondo. I processi attentivi possono imporsi sui processi pre-attentivi. Questo meccanismo sembra funzionare a livello delle singole cellule: quando una scimmia presta attenzione ad uno stimolo le registrazioni mostrano una soppressione delle risposte delle cellule in IT allo stimolo ignorato.
Processi analoghi sembrano verificarsi nella memoria visiva a breve termine. Una precedente presentazione di stimoli visivi può avere un effetto di soppressione o miglioramento della risposta neuronale. Ripetute presentazioni di uno stimolo riducono le risposte dei neuroni in IT allo stesso stimolo. Ciò suggerisce che si tratta di un processo automatico che agisce come meccanismo di figura sfondo.
L’aumento di scarica dei neuroni dell’area IT nei compiti attentivi associati alla memoria a breve termine
L’aumento di attività neuronale si verifica solo quando la scimmia svolge attivamente un compito di memoria a breve termine come un compito di associazione ritardata in cui gli animali devono identificare uno stimolo presentato on precedenza.
Alcuni neuroni nell’area IT della scimmia mantengono un’elevata frequenza di scarica durante l’intervallo di ritenzione: questa attività potrebbe essere un aiuto alla formazione della memoria a breve termine (che secondo Desimone avviene per un processo top down). Come i neuroni IT, alcuni neuroni nella corteccia prefrontale laterale conservano un’elevata frequenza di risposta durante l’intervallo di ritenzione. Questo mantenimento della scarica è temporaneamente interrotto da stimoli addizionali durante l’intervallo di ritenzione, ma l’attività riprende rapidamente.
I processi di memoria pre attentivi sono sensibili alla ripetizione dello stimolo e automaticamente influenzano i processi visivi verso stimoli nuovi e poco frequenti. I processi attentivi sono importanti quando cerchiamo uno stimolo particolare .
Aree coinvolte nella nella rievocazione di immagini visive dalla memoria a lungo termine
Sebbene si pensi che la memoria a lungo termine sia mediata prevalentemente dall’ippocampo e dalle aree associative, tutte queste hanno estese proiezioni dirette ed indirette verso il sistema visivo. Studi con PET e fMRI hanno mostrato che nella rievocazione degli oggetti, le aree visive superiori sono attive e che lesioni a queste aree danneggiano il processo di rievocazione. C’è stato però un dibattito sulla possibile attivazione delle prime aree visive V1 e V2. Al momento sembra che tutte le aree visive corticali siano attive durante le immagini mentali e nella rievocazione di immagini visive dalla memoria a lungo termine.